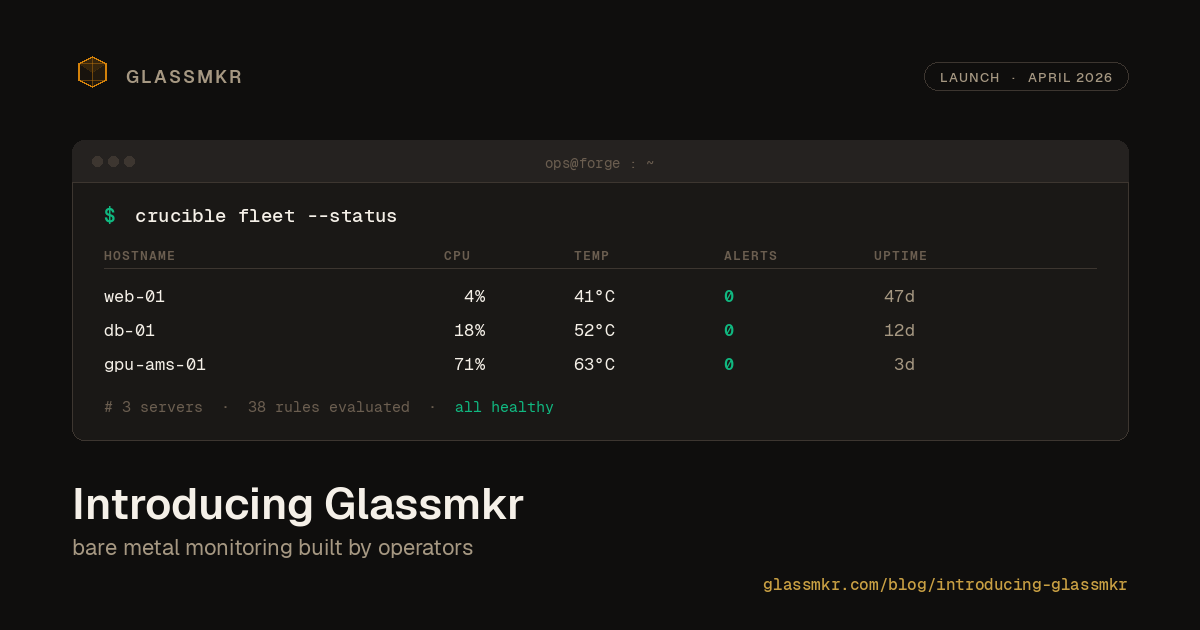
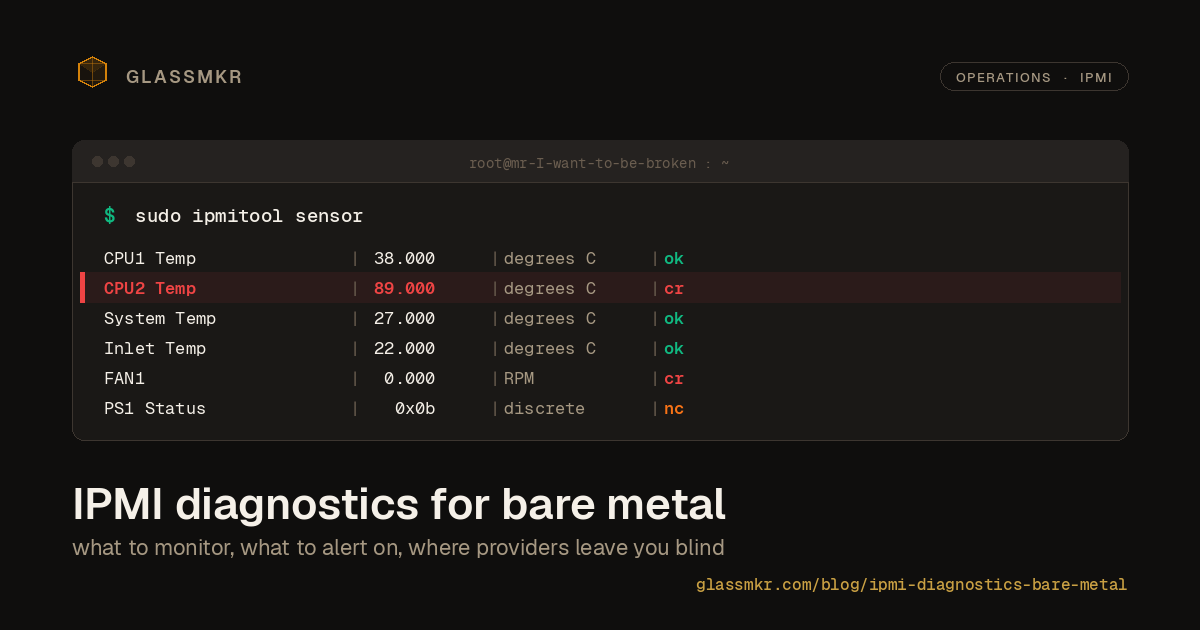
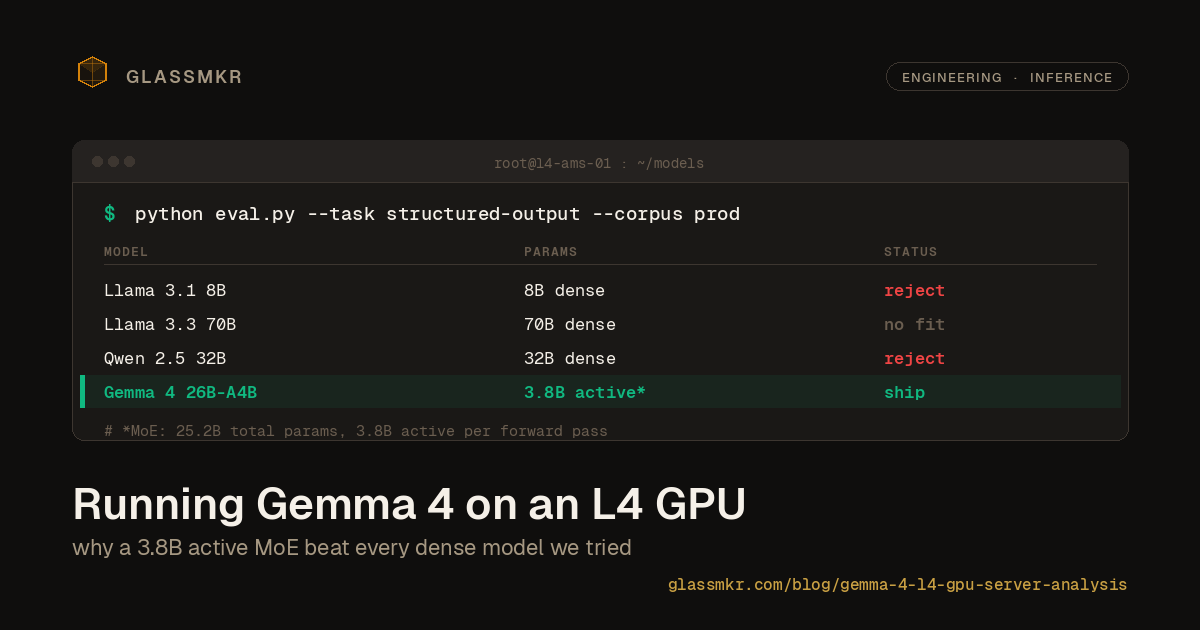
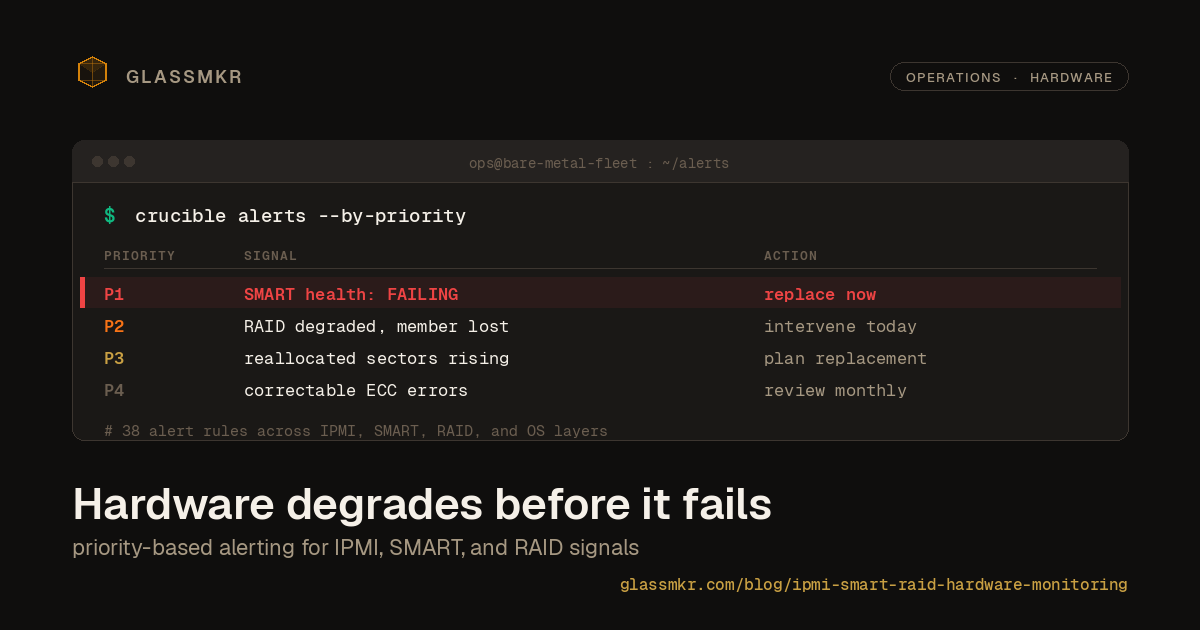
One account key, zero per-host secrets
Most fleets onboard into monitoring by copying one powerful credential onto every box. glassmkr-crucible enroll does the opposite: one account key stays in your control plane, each host self-registers by a stable machine ID and holds only its own collector key, and running the automation twice does nothing.